
edwith_python_(3)기초 통계값 확인하기
Updated:
edwith 부스트코스 파이썬으로 시작하는 데이터 사이언스 를 공부하는 과정입니다.
지난 포스트 ![]() edwith_python_(2)결측치 제거 및 데이터 요약
edwith_python_(2)결측치 제거 및 데이터 요약
1.11 기초 통계값 보기
1.11.1 기초 통계 수치
“위도” 컬럼 값의 평균 구하기
df["위도"].mean()
“위도” 컬럼 값의 중앙값 구하기
df["위도"].median()
“위도” 컬럼 값의 최댓값 구하기
df["위도"].max()
“위도” 컬럼 값의 최솟값 구하기
df["위도"].min()
“위도” 컬럼 값의 개수 구하기
df["위도"].count()
1.11.2 기초 통계값 요약하기 - describe
“위도” 컬럼 값을 describe로 요약하기
df["위도"].describe()
*결과*
count 91335.000000
mean 36.624711
std 1.041361
min 33.219290
25% 35.811830
50% 37.234652
75% 37.507463
max 38.499659
Name: 위도, dtype: float64
50% 값 = median(중앙값)
“위도”와 “경도” 2개 컬럼을 describe로 요약하기
df[["위도", "경도"]].describe()
*결과*
| 위도 | 경도 | |
|---|---|---|
| count | 91335.000000 | 91335.000000 |
| mean | 36.624711 | 127.487524 |
| std | 1.041361 | 0.842877 |
| min | 33.219290 | 124.717632 |
| 25% | 35.811830 | 126.914297 |
| 50% | 37.234652 | 127.084550 |
| 75% | 37.507463 | 128.108919 |
| max | 38.499659 | 130.909912 |
문자열 데이터 타입 요약하기
df.describe(include="object")
*결과*
| 상호명 | 상권업종대분류코드 | 상권업종대분류명 | 상권업종중분류코드 | 상권업종중분류명 | 상권업종소분류코드 | 상권업종소분류명 | 시도명 | 시군구명 | 행정동명 | 법정동명 | 대지구분명 | 지번주소 | 도로명 | 건물관리번호 | 도로명주소 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 91335 | 91335 | 91335 | 91335 | 91335 | 91335 | 91335 | 90956 | 90956 | 90956 | 91280 | 91335 | 91335 | 91335 | 91335 | 91335 |
| unique | 56910 | 1 | 1 | 5 | 5 | 34 | 34 | 17 | 228 | 2791 | 2822 | 2 | 53118 | 16610 | 54142 | 54031 |
| top | 리원 | S | 의료 | S01 | 병원 | S02A01 | 약국 | 경기도 | 서구 | 중앙동 | 중동 | 대지 | 서울특별시 동대문구 제기동 965-1 | 서울특별시 강남구 강남대로 | 1123010300109650001031604 | 서울특별시 동대문구 약령중앙로8길 10 |
| freq | 152 | 91335 | 91335 | 60774 | 60774 | 18964 | 18964 | 21374 | 3165 | 1856 | 874 | 91213 | 198 | 326 | 198 | 198 |
문자열 타입의 요약정보 *결측치는 제외하고 보여줌
unique: 중복값을 제외한 개수 top: 가장 많이 등장한 object
freq: ‘top’ 값이 등장한 빈도수
1.11.3 중복제거한 값 보기
“상권업종중분류명”컬럼 값의 중복 제거한 값 보기
df["상권업종중분류명"].unique()
*결과*
array(['병원', '약국/한약방', '수의업', '유사의료업', '의료관련서비스업'], dtype=object)
“상권업종중분류명”컬럼 값의 Unique 값 개수 카운팅
df["상권업종중분류명"].nunique()
*결과*
5
len(df[“상권업종중분류명”].unique()) 와 같은 의미
1.11.4 그룹화된 요약값 보기 - value_counts
“시도명” 컬럼의 도시명을 종류별로 개수 카운팅
city = df["시도명"].value_counts()
city
*결과*
경기도 21374
서울특별시 18943
부산광역시 6473
경상남도 4973
인천광역시 4722
대구광역시 4597
경상북도 4141
전라북도 3894
충청남도 3578
전라남도 3224
광주광역시 3214
대전광역시 3067
충청북도 2677
강원도 2634
울산광역시 1997
제주특별자치도 1095
세종특별자치시 353
Name: 시도명, dtype: int64
각각의 도시명 개수가 차지하는 비율 나타내어 city_normalize 변수에 담기
city_normalize = df["시도명"].value_counts(normalize=True)
city_normalize
*결과*
경기도 0.234993
서울특별시 0.208266
부산광역시 0.071166
경상남도 0.054675
인천광역시 0.051915
대구광역시 0.050541
경상북도 0.045528
전라북도 0.042812
충청남도 0.039338
전라남도 0.035446
광주광역시 0.035336
대전광역시 0.033720
충청북도 0.029432
강원도 0.028959
울산광역시 0.021956
제주특별자치도 0.012039
세종특별자치시 0.003881
Name: 시도명, dtype: float64
위 내용을 막대그래프로 나타내기
city.plot.barh(rot = 0)
*결과*
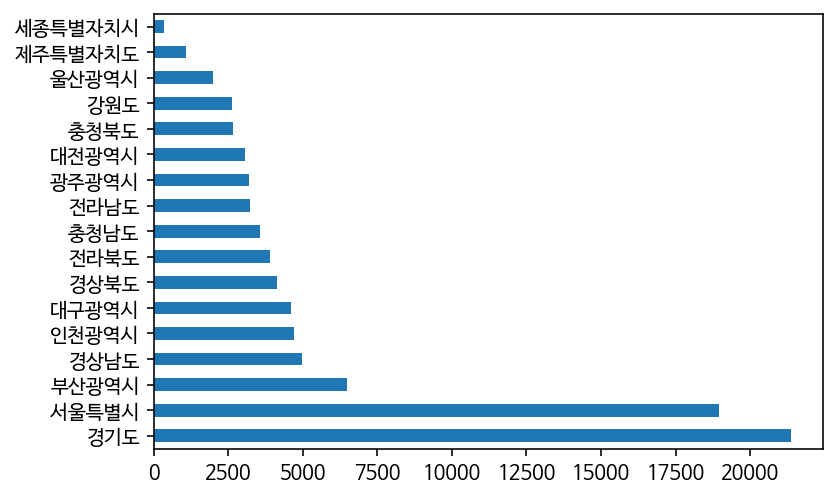
bar: 세로막대 그래프
barh: 가로막대 그래프
rot : 축 이름 회전시킬 각도
위 내용을 파이그래프로 나타내기
city_normalize.plot.pie(figsize=(6,6))
*결과*

파이 그래프는 수치를 정확하게 비교하기 어려워서 잘 사용되지 않음
seaborn의 countplot으로 나타내기
c = sns.countplot(data=df, y="시도명")
*결과*

seaborn으로 그래프를 그리면 시각적으로 예쁜 그래프를 그릴 수 있음
R에서 ggplot같은 느낌?
다음 포스트 ![]() edwith_python_(4)데이터 색인하기
edwith_python_(4)데이터 색인하기
Leave a comment